

| October 16, 2018
QCon2018上海站软件技术大会,我作为Java专题出品人,帮助组委会筹划了Java专题。 作为软件开发者,这样的技术盛宴自然是不能错过。这次在上海也可以心无旁骛聆听会议讲演和学习先进的技术。
这篇文章中,我主要分享Julien Viet的 Vertx 高性能演讲 的学习心得。
Julien有两个演讲场次,第一场的内容是Vertx技术概览,主要受众为对Vertx稍有了解,以及对Nodejs或者响应式编程感兴趣的Java开发者。第二场,即我要谈到的这场,则是Vertx高性能的精华所在。 因为一些原因(后面会提到),这场的内容slides直到会议当天,Julien才全部完成,也就是说,这场的技术内容是绝对新鲜的,来自一线的深入技术经验分享。
之前我在开源中间件公众号文章中提到过,Vertx在各种语言开发的框架中,各项测试都有很好的成绩。 要知道,能在Techempower性能榜单中排在前面并不容易,得和C/C++等语言同台较量,必须要做好每一点的优化,不放过微小的细节。榜单上还有很多专门为打榜而生的一些开发框架。所以说,一个开发框架或者软件项目,能有百万级用户,也就是易用而又全面,还能跻身前列,就是非常不错的成绩。
Vertx能够取得好成绩,肯定需要进行反复而持久的性能优化。Julien的分享就是这样,充分来自于他和Vertx核心团队经验。 我再现场仔细听了他的分享之后,后研究会议Slides多次,以及查看会议现场拍下的照片,写下一些心得体会。
一 性能优化的一些关键点
这部分占据了slides的主要内容,也是性能优化的重要关注点:
- 避免阻塞。工作线程阻塞,是造成整个系统吞吐量下降的主要原因。Vertx作为响应式开发框架,自然在这点上有先天优势。
- 代码内联。代码内联是指把调用方法内联(inline)到调用代码片中,从而减少方法调用引起的开销。这个过程是JVM自动完成的,但JVM决定是否进行内联是动态的,而且有前提条件,所以开发者如何写代码,也是让JVM优化的过程。
- Batch to amortise costs直接翻译是批量处理分摊成。给出一个例子,对一个连接进行读取前处理和读通道操作,放在一个函数调用中,可以优化性能。
- 最快的代码是从不运行。这里的不运行是指,一段代码可能是通过不合理的调用方法激发的,可以优化成合理的方式,从而避免不必要的开销。
- 减少对象初始化和资源分配。如果可以复用已经初始化的资源,比如对象池,数组等。这样也可以减少GC负担。
- 缓存昂贵的操作过程。对于费时费力的计算过程,对其结果进行缓存,这样就不必每次都进行。以上都给出了Vertx优化实战代码范例。
- 加快HTTP头部编码过程
- 缓存复杂的状态
- 直接内存拷贝,避免对象内存拷贝,即NIO的zero copy
- 高效的刷新方法,最小化使用高昂的系统调用方法
- RxJava的支持,高效率的数据获取。
- Domain socket和对象代理的支持
二 优化工具的演示
这部分在slides里只有文字简单描述,现场Julien给进行了Demo演示过程。
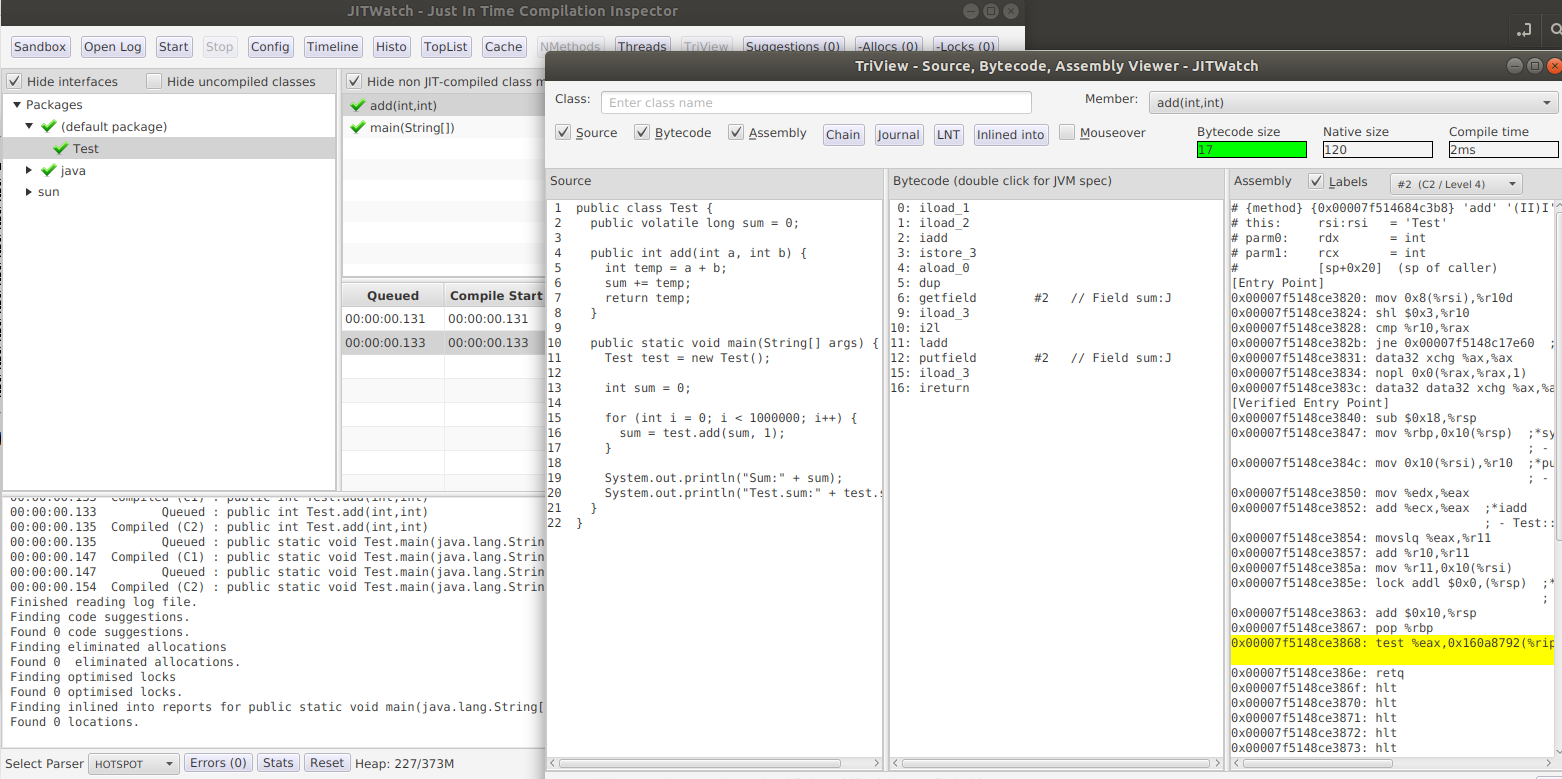
1. Jitwatch
这个工具是用来对JVM编译过程进行分析的利器,Java编译过程主要是JIT(Just in time)即时编译器。一个程序在开始时是解释执行,当JVM发现有些代码被反复调用时,动态进行编译,从而加快后续的执行速度。JIT和AOT(Ahead of time)进行对应,后者为运行前编译,比如C语言程序都是先编译后执行。(关于Java AOT可以参考之前公众号文章Java新优特性之Jlink和GraalVM)。
JitWatch就可以帮助深入分析编译过程和生成机器代码,从而在低层次进行性能调优。还可以给出过程图表,对象方法机器码大小排序,代码缓存布局图,编译线程活动图等等各种深层次但直观的内容。
这个工具是JavaFX写成的,这里我给出一个简单的使用说明:
JitWatch是AdoptOpenJDK团队维护的开源项目,可以从https://github.com/AdoptOpenJDK/jitwatch获得,下载后使用maven进行编译和运行。
/tools$ git clone https://github.com/AdoptOpenJDK/jitwatch
/tools$ cd jitwatch/
/tools/jitwatch$ mvn install
/tools/jitwatch$ mvn exec:java
Jitwatch窗口就会弹出。这时就可以进行jit过程的log分析了。
生成JIT log,我们需要使用hsdis工具,以Oracle JDK8为例。
$ java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -version
Java HotSpot(TM) 64-Bit Server VM warning: PrintAssembly is enabled; turning on DebugNonSafepoints to gain additional output
Could not load hsdis-amd64.so; library not loadable; PrintAssembly is disabled
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
这时说明并没有安装hsdis工具
从http://lafo.ssw.uni-linz.ac.at/hsdis/att/ 下载hsdis-amd64.so文件(也可以自行编译,此处省略直接使用编译好的so文件)
拷贝到JDK8的目录/jre/lib/amd64/server中(Linux环境,其他系统会有不同)
然后再运行
$ java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -version
Java HotSpot(TM) 64-Bit Server VM warning: PrintAssembly is enabled; turning on DebugNonSafepoints to gain additional output
Loaded disassembler from /x1/java/javalib/jdk1.8.0_171/jre/lib/amd64/server/hsdis-amd64.so
Decoding compiled method 0x00007f500d101310:
Code:
[Disassembling for mach='i386:x86-64']
...
看到hsdis工具已经启用了,这时就可以生成JIT日志文件。 我们编写一个多次循环的Java程序,用命令行启动,带入参数生成JIT日志
$ java -server -XX:+UnlockDiagnosticVMOptions -XX:+TraceClassLoading -XX:+PrintAssembly -XX:+LogCompilation -XX:LogFile=test_jit.log Test
在JitWatch窗口中打开test_jit.log日志文件,并设置测试源码和JDK源码路径,然后start,完成后就可以看到Java代码,对应的JVM编码和汇编机器码的对应关系了。
2. Async-profiler
这个工具是用来分析程序执行的过程,获取性能数据,用火焰图(FlameGraph, https://github.com/brendangregg/FlameGraph)展现出来
Async-profile的源码在https://github.com/jvm-profiling-tools/async-profiler,也可以直接获得执行文件。当前最新版本为1.4。
启动方式有两种:
一种针对长时间运行的Java进程,通过jps获得进程号,然后使用profile.sh attach到进程上进行数据获取和分析;
$ ./profiler.sh -d 30 8983 //针对进程8983运行30秒
还有一种是针对短时间运行的进程,可以使用java agent运行时挂载
$ java -agentpath:/path/to/libasyncProfiler.so=start,svg,file=profile.svg
可以看到,这个参数指定了对应的so文件,给出的命令start,以及生成svg图形文件。
在我的机器上,需要对event_参数进行设置,否则会出现错误提示"perf_event_open failed: Permission denied"
$ echo 1 | sudo tee /proc/sys/kernel/perf_event_paranoid
[sudo] password for user:
1
$ cat /proc/sys/kernel/perf_event_paranoid
1
对Test执行
$ java -agentpath:/x1/temp/play/jit/async-profiler-1.4/build/libasyncProfiler.so=start,svg,file=profile.svg Test
Sum:1000000
Test.sum:500000500000
得到火焰图 profile.svg,通过观察火焰图,可以得知哪些方法占用了较大比例的CPU时长资源。平顶的说明该方法耗时多,占用资源比例大(范例图为简单程序)。

三 异步JDBC和pipeline方式访问数据库
在Vertx提交给Techempower的测试方案中,使用了Vertx开发团队维护的reactive postgre client项目。
如果说Vertx在测试中耍了什么“花招”的话,我认为就是这个部分了。关于这一点在Slide中也有较详尽的描述,在访问数据库时,Vertx使用了批量访问数据库的pipeline方式。
不过,在Techempower指定的规则中,已经明确提出可以使用pipeline的方式,所以并不违反规则。
目前Redis,Mongodb等NoSQL数据都有pipeline方式的支持。对于关系数据库,Postgres很早(应该是9.6版本)就提供pipeline方法的支持,Oracle和Mysql我也查到了一些技术说明,如果有兴趣的朋友可以进一步尝试并研究。
关于数据库访问这个技术点,我更为关心的是异步数据库访问方式,即异步JDBC。
目前大多数异步响应式框架在访问数据库时,依然是使用标准的JDBC驱动,只是框架自身提供了事件驱动机制,比如Vertx的JDBC客户端
Vertx在性能评测中使用的响应式postgres客户端,是直接写二进制和postgres服务器进行对话的。目前版本为0.10.6,一段简单查询代码如下:
// A simple query
client.query("SELECT * FROM users WHERE id='julien'", ar -> {
if (ar.succeeded()) {
PgResult<Row> result = ar.result();
System.out.println("Got " + result.size() + " results ");
} else {
System.out.println("Failure: " + ar.cause().getMessage());
}
// Now close the pool
client.close();
});
可以看出使用函数式编程的用法,相当方便和高效。
而这一领域最令人期待的是Oracle领导的ADBA项目 使用了jdk.incubator.sql2这样的包名,目标是成为未来JDK异步JDBC接口的标准。
“ADBA is Asynchronous Database Access, a non-blocking database access api that Oracle is proposing as a Java standard. “
调用代码稍微复杂,关键片段如下
try (DataSource ds = factory.builder()
.url(url)
.username(user)
.password(password)
.build();
Session conn = ds.getSession(t -> System.out.println("ERROR: " + t.getMessage()))) {
// get a TransactionCompletion
TransactionCompletion trans = conn.transactionCompletion();
// select the EMPNO of CLARK
CompletionStage<Integer> idF = conn.<Integer>rowOperation("select empno, ename from emp where ename = ? for update")
.set("1", "CLARK", AdbaType.VARCHAR)
.collect(Collector.of(
() -> new int[1],
(a, r) -> {a[0] = r.at("empno").get(Integer.class); },
(l, r) -> null,
a -> a[0])
)
.submit()
.getCompletionStage();
// update CLARK to work in department 50
conn.<Long>rowCountOperation("update emp set deptno = ? where empno = ?")
.set("1", 50, AdbaType.INTEGER)
.set("2", idF, AdbaType.INTEGER)
.apply(c -> {
if (c.getCount() != 1L) {
trans.setRollbackOnly();
throw new SqlException("updated wrong number of rows", null, null, -1, null, -1);
}
return c.getCount();
})
.onError(t -> t.printStackTrace())
.submit();
conn.catchErrors(); // resume normal execution if there were any errors
conn.commitMaybeRollback(trans); // commit (or rollback) the transaction
}
除了函数式编程,还使用了JDK的线程调度框架。
早在JDK9时就进入代码库sandbox中,但一直到JDK11发布,也没有最终成型。目前看在JDK12发布时也不一定能完成。
我认为,AJDBC方式是最合理的异步响应式JDBC方案,这样可以调动数据库厂商的积极性来主动提供Java驱动,进而优化数据库访问能力。
四 大会总结
一个主题演讲,学习者在参会之前通过查看演讲大纲了解内容,并查阅有关资料预习,可以理解10%的内容;现场聆听可以理解40%的内容;通过观看Slide和视频,进一步领悟30%,再通过后续不断的琢磨,思考和实践,完成剩余20%的学习。那么这个演讲无疑就非常成功,学习者也会得到非常多的收获。
对应的,一场技术大会,如果其中有三分之一的内容,能让从业多年的开发者反复思考,我想就是非常成功的大会,这次QCon应该说实现了。
作为Java专题出品人,我把目标定位为全球知名Java开源项目和技术专题,前后邀请了很多领域内专家。不巧的是,这次大会恰好和位于北美的OracleCodeOne大会与欧洲的EclipseCon欧洲时间重合,所以有些国外的Java专家无法成行。而Julien也因为护照到期而迟迟未能确定行程,只到会议那一周才拿到签证。
还好一切顺利,Julien Viet一人分享了2个技术主题演讲,来自阿里中间件的李云老师的Dubbo ServiceMesh精彩分享,使得本次Java专题能称得上全球范围内技术领先。微软的JonathanGiles的构建JavaAPI艺术演讲也非常出色,只是因为Keynote主题的老师因飞机延误未及时到场,被调换到上午,这样Java专题只有三场略微遗憾。
昨日Julien和我沟通:“I got plenty of positive feedback on the slides for the performance talk”,我能读出他的喜悦心情,他的推文在twitter上也受到很多赞赏和关注。
我想能够促进软件科技的一点进步和知识传播,也可以为这次出品人工作画上一个句号了。